Owostack makes billing decisions on the request path. For a metered feature, a single check may need to read subscription state, current usage, credits, reset windows, overage rules, entitlements, and customer-level billing configuration, then decide whether to allow usage and how that usage should be accounted for.
That creates a few immediate constraints. The check has to be fast enough to sit in front of an application request. The usage state has to stay correct under concurrency. The system has to preserve enough billing context to invoice that usage later under the right plan, pricing, and period boundaries. And the slower path still has to handle invoice generation, payment attempts, retries, reconciliation, and recovery from partial failure. We did not want to solve all of that with one store or one execution model.
The shape of the system
If I had to summarize Owostack in one diagram, it would look like this:
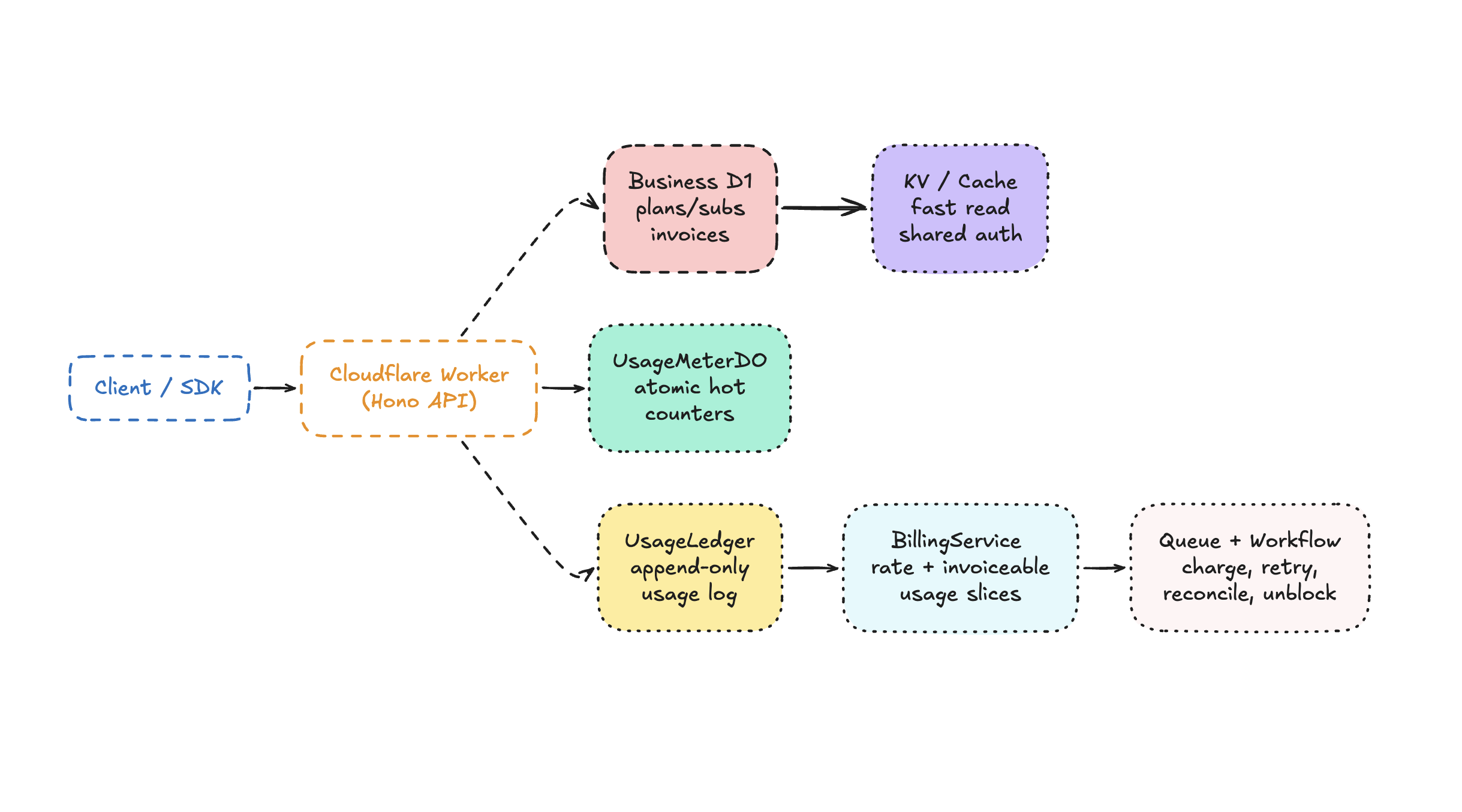
Each primitive gets the part of the problem it is actually good at.
The Worker is the decision engine, not the whole system
At the edge, Owostack runs as a Cloudflare Worker. The Worker sits in front of the whole system and assembles the decision.
One compact binding block tells the story pretty well:
type Env = {
DB: D1Database;
DB_AUTH: D1Database;
CACHE: KVNamespace;
USAGE_METER: DurableObjectNamespace;
USAGE_LEDGER: DurableObjectNamespace;
OVERAGE_BILLING_WORKFLOW: Workflow;
OVERAGE_BILLING_QUEUE: Queue;
};That is almost the whole architecture in miniature: two D1 databases, one cache surface, one hot mutable meter, one durable usage ledger, and a separate path for slow billing work.
The Worker’s job is orchestration. It authenticates the caller, resolves the organization and customer, loads the active subscription and plan feature config, decides whether to check a credit system, metered allowance, overage rules, or add-on balance, talks to Durable Objects when atomic usage state matters, and defers slower side effects with waitUntil.
This sounds obvious, but it is easy to get wrong. A lot of edge systems either become too thin and push all the logic elsewhere, or they become too fat and start pretending the Worker itself is the durable system.
We wanted the Worker to be the place where the decision is assembled, but not the place where all state lives.
We use two D1 databases on purpose
We use one D1 database for per-environment business data, and another for shared auth and organization identity.
We wanted sandbox and live business data to be isolated. Test invoices, test subscriptions, and live invoices should never share the same business store. But auth is a different concern: users and organizations are identity data, not billing-environment data.
That gives us a cleaner model. A user signs in once. An organization exists once. But the business state for that organization can differ by environment.
This separation also made our code less confused. Billing flows are already hard enough without mixing environment scoping into every auth query.
Why metering lives in Durable Objects instead of D1
A Durable Object is Cloudflare’s actor-like primitive for stateful compute. Each object has a stable identity and its own local storage. Requests sent to the same object are processed sequentially, which makes it useful for small pieces of mutable state that must stay correct under concurrency.
That is why it fits metering well. For a given customer, usage checks and usage mutation need to happen against the same state, in order, without concurrent requests racing each other.
If two requests arrive at the same time for a feature with one unit remaining, you cannot afford a race where both requests read the old balance, both decide they are allowed, and both write a new state later. That is how “100 included requests” turns into “102 requests and a support thread.”
The reason our hot-path usage state lives in a customer-scoped Durable Object.
Each customer gets a single serialized execution lane for mutable quota state.
Inside the DO we store per-feature state like:
usage, balance, limit, lastReset, and rolloverBalance.
And we let the DO answer the atomic question: is this usage allowed right now, and if so, what does the new balance look like?
This buys us three things immediately: atomicity for concurrent usage checks and tracks, low-latency hot state close to the request path, and per-customer isolation so one noisy customer does not serialize all other customers.
The DO also owns reset alarms, rollover behavior, and plan-scope-sensitive resets. That is another subtle place where a naive relational design becomes awkward fast. Reset windows are stateful and time-based. Durable Object alarms fit that model much better than asking every request to recalculate everything from scratch forever.
But the meter is not the invoice ledger
A single primitive almost worked here. We could have tried to derive invoices directly from the hot customer meter.
We did not.
That is because the usage meter answers a different question:
Can this customer consume this unit right now?
Billing later needs a different answer:
Which usage slice, under which plan and pricing snapshot, is still unbilled?
That is why we also have a separate usage ledger Durable Object.
This object is organization-scoped, not customer-scoped.
That split is one of my favorite parts of the design.
The meter object is optimized for customer-local atomic mutation.
The ledger object is optimized for append-only, queryable accounting history with billing context attached: customer, feature, amount, billing period, subscription, plan, pricing snapshot, and invoice linkage.
In other words, the meter knows whether usage is allowed. The ledger knows what exactly happened, under which commercial terms, and whether we have already invoiced it.
That distinction became even more important once we started handling plan switches and mid-period pricing changes. You cannot just sum “extra usage” anymore. You need to know whether 400 units belong to the old plan, the new plan, or an old pricing snapshot inside the same subscription window.
That is why we persist pricing snapshots with usage records instead of pretending today’s plan definition can always explain yesterday’s charge.
The real /check path
The public story is simple: call check and get an answer. The internal story is a little more interesting.
For a metered feature, the route does roughly this:
1. Resolve customer, feature, subscription, and plan feature
2. Compute the active reset window
3. Resolve usage scope for the active subscription/plan
4. Ask UsageMeterDO for the current atomic state
5. If the DO has no state yet, hydrate it from UsageLedgerDO
6. If included balance is exhausted:
- try add-on credits
- otherwise evaluate overage policy and guards
7. Return a decision immediately
8. If this was a consuming check, persist usage asynchronouslyThat hydration step is important. We do not trust local in-memory state alone, because Durable Objects can cold start or migrate. When a meter comes up without state, we rebuild it from the authoritative usage ledger for the current billing scope.
That lets us keep the fast path fast without treating the hot object as irreplaceable.
That pattern is worth calling out because it captures the overall architecture: Durable Objects for speed and atomicity, the ledger for durable recovery, and the Worker for composition.
No single layer is trusted to be everything.
Billing only works if “unbilled” means something precise
One lesson we learned the hard way is that “show me this customer’s usage” is not a single metric. Total usage this period, current included consumption, billable overage, unbilled overage, and already invoiced overage are all different values.
Our BillingService now computes unbilled usage by grouping records on the exact billing boundary:
- feature
- period start and end
- subscription
- plan
- pricing snapshot
Then it rates the delta between previous cumulative usage and current cumulative usage, instead of re-rating the uninvoiced slice as if it were the customer’s entire period history.
That subtlety matters a lot after threshold invoices. If a customer already crossed the included limit, got billed once, and then consumed 90 more units, those 90 units still need to show up as unbilled follow-up overage. The system cannot accidentally treat them like “fresh included usage.”
Slow money-moving work belongs outside the request
The fast path should decide access. It should not also try to charge a card, retry provider calls, reconcile external subscription periods, and keep a durable retry history while the caller waits.
That is why Owostack uses Cloudflare Queues and Workflows for the overage billing path.
The queue is how we fan work out safely.
The workflow is how we make the multi-step billing path durable. It calculates the uninvoiced usage slice, generates an invoice, attempts payment with the active provider, marks success or leaves the invoice open, blocks or unblocks customer overage state when needed, and reconciles subscription periods and cache afterwards.
That path is exactly the kind of thing Workflows are good at. It has multiple steps, it can fail halfway through, provider APIs are slow and flaky, retries need to be durable, and the business logic should survive process restarts.
If we had left that as a plain background function or an in-request promise chain, it would have been much harder to reason about failure modes.
Here is the architecture in a second diagram:
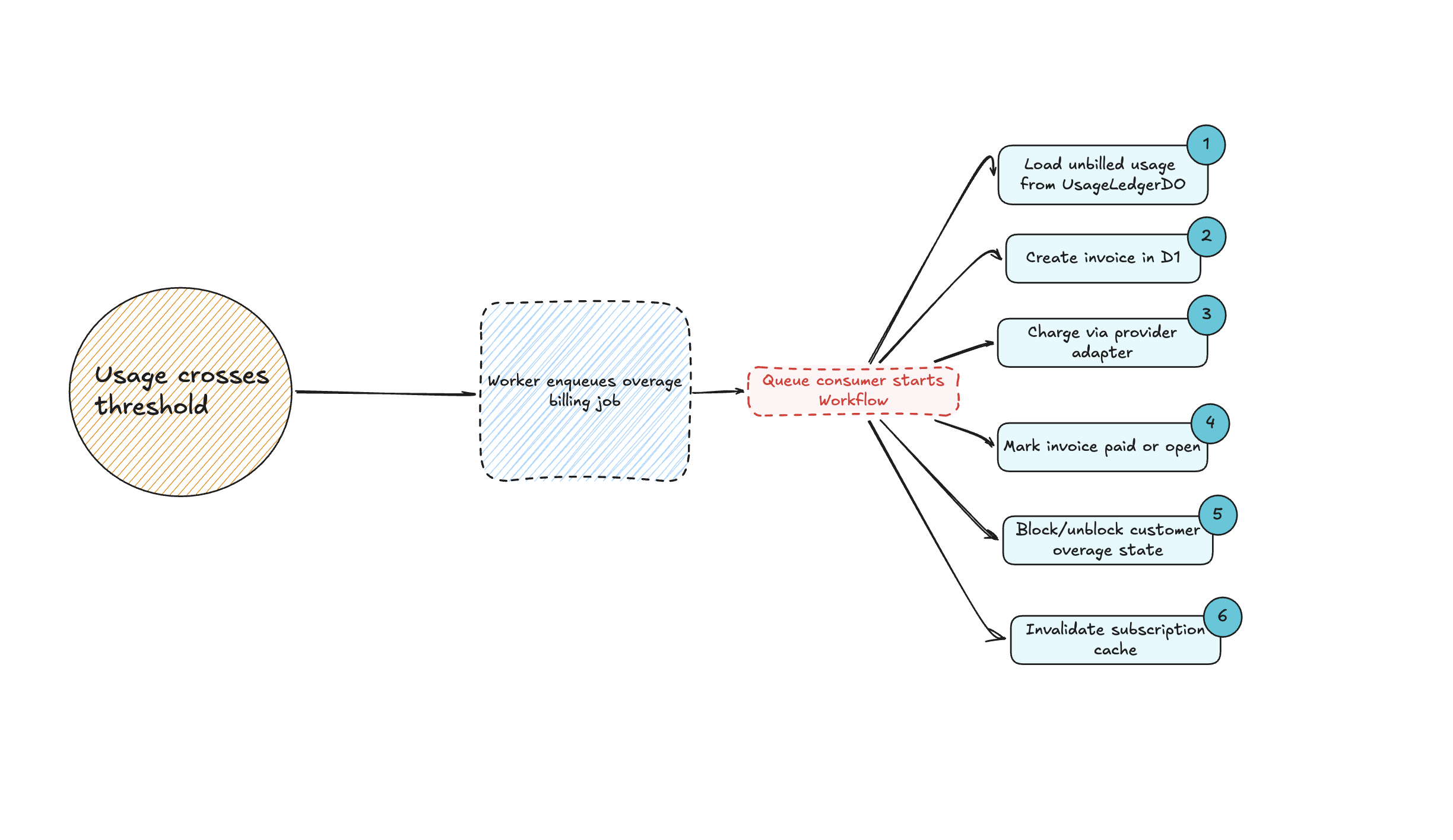
That keeps the core API honest: entitlement checks stay responsive, billing work becomes durable, and failures become visible and retryable.
The tradeoff: the architecture is better, but the debugging is sharper
I do not want to romanticize this architecture too much. It solved real problems, but it introduced new ones.
When you split the system this way, debugging gets more precise and more annoying at the same time.
A bug now have multiple places to spawn. It might be that the Worker made the wrong access decision, the customer meter had stale config, the usage ledger grouped a billing slice incorrectly, the overage workflow retried against the wrong provider state, or the environment bindings were correct in one deployment and wrong in another.
That is the price of specialization. The system becomes more correct under load, but less hand-waveable.
The upside is that the boundaries become explicit. When something goes wrong, we can usually ask a better question: was the access decision wrong, was the metered state wrong, was the invoiceable history wrong, or was the durable billing process wrong?
That is a much better place to debug from than one giant blob of “billing code.”
Those are the decisions that made the Cloudflare architecture work for us.
Yes Cloudflare is magical, and because the primitives lined up unusually well with the actual shape of the product.
not one primitive that solved everything, but a set of primitives we could compose around to build a durable system